Технология интеллектуального поиска по электронным обучающим материалам
По мере роста количеств информации вследствие технического прогресса, все большую важность приобретают технологии поиска необходимой информации среди больших ее объемов. В том числе это касается и учебного процесса: получаемые студентом знания часто оказываются устаревшими, в лучшем случае — на несколько лет, тогда как для применения их на практике требуется иметь хорошее представление о текущем состоянии технологии и ее направлениях развития. Наиболее остро эта проблема стоит для студентов специальностей, связанных с вычислительной техникой. К тому же, для преподавателей профильных предметов на этих специальностях также стоит задача предельной актуализации своих знаний.Хорошим источником информации как для студентов, так и для преподавателей являются информационные поисковые системы. Однако современные поисковые системы имеют одну общую проблему: зачастую количество информационного мусора в получаемом результате на порядки превышает количество полезной информации. Предлагаемая в данной статье методика поиска не является принципиально новой, однако по каким-то причинам не разработано ни одной действующей реализации поисковой системы на основе данной методики.Рассмотрим процесс работы современной поисковой системы. Поисковый робот-«паук» по очереди скачивает текстовые данные из сети, просматривает, находит ссылки и повторяет то же самое для найденных ссылок. При этом каждый документ индексируется тем или иным образом, чаще всего методом сопоставления документа со словами в словаре (установление отношения «слово N встречается в документе M»), либо подсчета частот вхождений слов (установление отношения «слово N встречается в документе M X раз») [1]. После этого становится возможным поиск по индексам на основании некоторого запроса к поисковой системе. Современные поисковые системы также имеют функции исправления ошибок в запросе, опережающий ввод и прочие полезные дополнения. Однако это все равно не спасает от неправильно сформированных запросов и субъективно преобладающего количества информационного мусора.Предлагаемая методика поиска состоит в нахождении документов, содержащих слова запроса в качестве наиболее характерных слов, которыми можно описать документ. Одним из подходов к реализации данной методики является описание каждого документа при помощи метаинформации (поле типа «ключевые слова»). Однако зачастую количество документов настолько велико, что назначать ключевые слова вручную нецелесообразно. В этом случае может помочь следующий подход.Примем утверждение, что каждый документ описывается набором характерных слов-терминов. Если слово часто встречается в данном документе и при этом не является общеупотребительным, то данное слово будем считать характерным термином. Поскольку документы содержат очень большое количество слов, для организации поиска желательно выделить максимальное количество информации в минимальном объеме данных. Для этого предлагается использовать подсчет частот встречаемости слов и характерных контекстов (сочетаний из 2-3 слов). Каждый характерный контекст в дальнейшем будем также называть «словом» для упрощения изложения. Перед подсчетом частот требуется, как минимум, исключить из документа так называемые стоп-слова (предлоги, местоимения, общеупотребительные глаголы), а также привести слова в начальную форму. Этим занимается специальная программа — стеммер. После этого при помощи достаточно простой процедуры выполняется подсчет частот. Полученный набор соответствий типа «слово k — частота v» будем называть образом документа: I1 = {k1 → v1, k2 → v2, k3 → v3}. (1) Если vn < 2, то с большой вероятностью слово kn представляет собой информационный мусор, который только ухудшит результат поиска. Такие слова следует исключить из дальнейшего рассмотрения. Так как в различных документах различное число слов, имеет смысл операция нормирования частот вхождений. Относительные частоты вычислим по формуле: 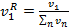 (2) Таким образом, после нормирования получаем:
(2) Таким образом, после нормирования получаем: 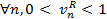 (3)
(3) 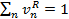 (4) По набору образов документов, полученных данным способом, уже можно осуществлять поиск, однако не вполне понятно по какому критерию оценивать релевантность результатов запросу. Кроме того, количество образов скорее всего будет очень значительным и выполнять поиск на основе линейного перебора окажется очень затратно.Для разрешения этой проблемы предлагается строить иерархический индекс (таксономию) по всему набору документов. В качестве алгоритма автоматической таксономии предлагается использовать универсальный алгоритм FRiS-Tax [2].Для использования данного алгоритма требуется ввести меру различия между двумя документами. Пусть сравниваются образы I1 и I2 документов D1 и D2 : I1 = {k1 → v1R, k2 → v2R, k3 → v3R} (5) I2 = {k2 → v2R, k3 → v3R, k4 → v4R} (6) Дополним каждый образ недостающими ключами другого образа: I1 = {k1 → v1R, k2 → v2R, k3 → v3R, k4 → 0} (7) I2 = {k1 → 0, k2 → v2R, k3 → v3R, k4 → v4R} (8) Введем меру различия между образами:
(4) По набору образов документов, полученных данным способом, уже можно осуществлять поиск, однако не вполне понятно по какому критерию оценивать релевантность результатов запросу. Кроме того, количество образов скорее всего будет очень значительным и выполнять поиск на основе линейного перебора окажется очень затратно.Для разрешения этой проблемы предлагается строить иерархический индекс (таксономию) по всему набору документов. В качестве алгоритма автоматической таксономии предлагается использовать универсальный алгоритм FRiS-Tax [2].Для использования данного алгоритма требуется ввести меру различия между двумя документами. Пусть сравниваются образы I1 и I2 документов D1 и D2 : I1 = {k1 → v1R, k2 → v2R, k3 → v3R} (5) I2 = {k2 → v2R, k3 → v3R, k4 → v4R} (6) Дополним каждый образ недостающими ключами другого образа: I1 = {k1 → v1R, k2 → v2R, k3 → v3R, k4 → 0} (7) I2 = {k1 → 0, k2 → v2R, k3 → v3R, k4 → v4R} (8) Введем меру различия между образами: 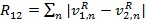 (9) где v1R и v2R — относительные частоты вхождений n-ных слов в 1 и 2 документе соответственно. Чем больше эта мера, тем больше различаются частотные спектры документов. Если положить, что слова каждого документа не встречаются в другом документе, то
(9) где v1R и v2R — относительные частоты вхождений n-ных слов в 1 и 2 документе соответственно. Чем больше эта мера, тем больше различаются частотные спектры документов. Если положить, что слова каждого документа не встречаются в другом документе, то 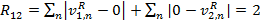 (10) Если же документы совпадают, то
(10) Если же документы совпадают, то 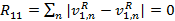 (11) Поэтому,
(11) Поэтому, 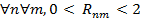 (12) Пусть рассматривается образ I3 документа D3. Согласно [2], вводится мера конкурентного сходства:
(12) Пусть рассматривается образ I3 документа D3. Согласно [2], вводится мера конкурентного сходства: 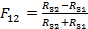 (13) Если F12 > 0, то I3 ближе к I1, чем к I2, если F12 < 0 — то наоборот. Если F12 = 0, то образ равноудален от I1 и I2. Если F12 = 1, то I1 = I3. Если F12 = -1, то I2 = I3.Согласно введенной мере сходства при помощи алгоритма FRiS-Tax образы документов группируются в кластеры. Каждый кластер имеет как минимум один наиболее характерный документ (т.н. столп, см. [2]), относительно которого остальные документы кластера имеют минимальное различие. Алгоритм строит несколько наборов кластеров для разных степеней детализации и вычисляет оценку качества кластеризации. Согласно [2], эта оценка локально максимальна тогда, когда разбиение может быть признано человеком-экспертом «разумным». Результаты, характеризующиеся локально максимальным качеством кластеризации, можно принять в качестве разных уровней иерархического индекса. В процессе поиска из запроса к поисковой системе аналогичным способом формируется характеристический образ. Этот образ сравнивается со всеми столпами верхнего уровня индекса, определяется наиболее близкий столп по мере близости и осуществляется переход на более низкий уровень индекса. Возможно, задать некоторый предел, при превышении которого документ будет считаться релевантным запросу. В этом случае требуется рекурсивный обход индекса. Сортировку документов по релевантности можно осуществлять по возрастанию меры различия между запросом и документом. Впрочем, как правило, если столп кластера релевантен запросу, то и остальные документы кластера так или иначе ему релевантны. После выяснения набора документов, можно провести полнотекстовый поиск по словам запроса, чтобы выяснить конкретные местоположения вхождений. Однако эта операция довольно затратна и как правило необязательна, поэтому необходимость ее использования под вопросом.Использование данного алгоритма и данной технологии дает три интересных побочных эффекта. Во-первых, для некоторого набора документов автоматически составляется каталог, поиск по которому зачастую может быть более продуктивным, чем посредством поискового запроса. Требуется только назначить названия для полученных кластеров. Во-вторых, получаем возможность использовать уточнение ключевых слов для выполнения запросов к внешним поисковым системам. Это актуально, поскольку увеличение количества ключевых слов при запросе к поисковой системе, как правило, ведет к увеличению количества полезных результатов. В-третьих, появляется возможность ассоциативного поиска, т.е. поиска похожих документов, как в исходном наборе, так и в сети посредством внешних поисковых систем. Данные возможности существенно улучшают функциональность поисковой системы. На данный момент автор занимается реализацией поисковой системы по описанной технологии с целью использования ее в составе системы управления учебными курсами ИДО НГТУ. Список литературы
(13) Если F12 > 0, то I3 ближе к I1, чем к I2, если F12 < 0 — то наоборот. Если F12 = 0, то образ равноудален от I1 и I2. Если F12 = 1, то I1 = I3. Если F12 = -1, то I2 = I3.Согласно введенной мере сходства при помощи алгоритма FRiS-Tax образы документов группируются в кластеры. Каждый кластер имеет как минимум один наиболее характерный документ (т.н. столп, см. [2]), относительно которого остальные документы кластера имеют минимальное различие. Алгоритм строит несколько наборов кластеров для разных степеней детализации и вычисляет оценку качества кластеризации. Согласно [2], эта оценка локально максимальна тогда, когда разбиение может быть признано человеком-экспертом «разумным». Результаты, характеризующиеся локально максимальным качеством кластеризации, можно принять в качестве разных уровней иерархического индекса. В процессе поиска из запроса к поисковой системе аналогичным способом формируется характеристический образ. Этот образ сравнивается со всеми столпами верхнего уровня индекса, определяется наиболее близкий столп по мере близости и осуществляется переход на более низкий уровень индекса. Возможно, задать некоторый предел, при превышении которого документ будет считаться релевантным запросу. В этом случае требуется рекурсивный обход индекса. Сортировку документов по релевантности можно осуществлять по возрастанию меры различия между запросом и документом. Впрочем, как правило, если столп кластера релевантен запросу, то и остальные документы кластера так или иначе ему релевантны. После выяснения набора документов, можно провести полнотекстовый поиск по словам запроса, чтобы выяснить конкретные местоположения вхождений. Однако эта операция довольно затратна и как правило необязательна, поэтому необходимость ее использования под вопросом.Использование данного алгоритма и данной технологии дает три интересных побочных эффекта. Во-первых, для некоторого набора документов автоматически составляется каталог, поиск по которому зачастую может быть более продуктивным, чем посредством поискового запроса. Требуется только назначить названия для полученных кластеров. Во-вторых, получаем возможность использовать уточнение ключевых слов для выполнения запросов к внешним поисковым системам. Это актуально, поскольку увеличение количества ключевых слов при запросе к поисковой системе, как правило, ведет к увеличению количества полезных результатов. В-третьих, появляется возможность ассоциативного поиска, т.е. поиска похожих документов, как в исходном наборе, так и в сети посредством внешних поисковых систем. Данные возможности существенно улучшают функциональность поисковой системы. На данный момент автор занимается реализацией поисковой системы по описанной технологии с целью использования ее в составе системы управления учебными курсами ИДО НГТУ. Список литературы
- Term frequency and weighting. [Электронный ресурс] – Электрон. текстовые дан. – Режим доступа: http://nlp.stanford.edu/IR-book/html/htmledition/term-frequency-and-weighting-1.html , свободный. – Загл. с экрана – Англ.
- Борисова И.А. Алгоритм таксономии FRiS-Tax. Научный вестник НГТУ, 2007, №3(28), стр. 3-12.